前几年就想聊一下 VirusTotal,但这个话题的优先级不是特别高,就一直没动手。 上个周末,正好在博客评论区与某些读者聊到 VirusTotal,当时也分享了一些经验,这几天就顺手把这篇教程写了。 本文既面向新手,也面向老手。对于【老手】,重点看本文后面的几个章节。 考虑到本文的读者,有些是技术菜鸟,先稍微介绍一下杀毒软件的原理。(技术老鸟可以跳过本章) 通俗而言,杀毒软件常用的招数有如下两个: 杀毒软件的厂商都有自己的安全研究团队,负责研究新出现的恶意软件(病毒、木马、蠕虫、勒索软件 ……)。每当发现一款新的恶意软件,研究人员会尝试找到该软件所具有的【独特指纹】,并加入到杀毒软件的【特征库】中。 所谓的【独特指纹】就是说——只有这个恶意软件才会包含该特征,其它软件【不】包含该特征。 当杀毒软件扫描磁盘时,就是根据自带的【特征库】进行检查,如果某个文件正好包含了【特征库】中“某某恶意软件”的特征,就会触发报警。 “基于特征的检测”有时候也被称作“【静态】分析” “基于特征的检测”相当于“事后诸葛亮”。也就是说,先得有恶意软件,然后研究人员才能去研究它。 这种玩法的一个巨大缺陷是——难以做到【事先】预防。因此,杀毒软件还会采用另一种措施来辅助——也就是所谓的“行为分析”。 一般来说,恶意软件总是会有一些比较奇怪的(反常的)行为。因此,杀毒软件会根据某个软件的行为,来判断其是否具有恶意。 “基于行为的检测”有时候也被称作“【动态】分析”。 传统的杀毒软件厂商,主要依靠安全研究人员来完成各种“静态分析 & 动态分析”。 随着 AI 的应用领域越来越广,如今有一个新的趋势——采用【机器学习】的方式完成上述工作。通俗地说,先让 AI 观察海量的“正常软件的行为”以及海量的“恶意软件的行为”,AI 自己会总结出这两者的差异。下次碰到一个全新的软件,AI 会给出自己的判断。 下面这本书【系统性】地介绍了“分析恶意软件的各种方法”,既包括俺刚才提到的“动态分析 & 静态分析”,还有各种深入的技术介绍。对该领域感兴趣的同学,可以去瞧一瞧。
《恶意代码分析实战》(Practical Malware Analysis——The Hands-On Guide to Dissecting Malicious Software)
(技术老鸟可以跳过本章) 所谓的【误报】就是——杀毒软件把正常文件当成恶意软件。 为啥会有误报捏?大致有两个原因——
比较常见的原因
前面聊了“特征分析”的原理——安全研究人员每当发现一款新的恶意软件,需要提取该恶意软件的【独特指纹】,加入到“特征库”。 在少数情况下,安全研究人员提取的【独特指纹】不够独特(不具有唯一性)。就会导致——某个正常文件碰巧也带有该指纹所具有的特征。在这种情况下,当杀毒软件扫描这个正常文件,就会【误报】。
比较少见的原因
“行为分析”有时候也会产生误报。举个例子: 在古老的 DOS 时代以及 Win9x 时代,“引导型病毒”很流行,这类病毒会感染(修改)硬盘的“主引导扇区”(MBR)。因此,很多杀毒软件会把“企图修改 MBR 的行为”视作恶意行为。但如果你使用分区工具调整磁盘分区,也会涉及到 MBR 的写操作,就有可能触发某些杀毒软件的【误报】。 所谓的【漏报】就是——杀毒软件把恶意软件当成正常文件。 为啥会有漏报捏? 前面聊了“特征分析”(静态分析)的原理——其具有【事后诸葛亮】的特点。假设出现某个【全新的】恶意软件,那么“特征分析”显然无法检测出它。再假设,这款全新的恶意软件,在行为方面也足够隐蔽,它还可以躲过“行为分析”(动态分析)。 在上述这种情况下,杀毒软件就会出现【漏报】。 最近一两个月,正好赶上肺炎疫情在全球爆发。套用医学界的术语——“误报”相当于“假阳性”;而“漏报”相当于“假阴性”。 “假阳性”只不过是【虚惊一场】;而“假阴性”则属于“有病当成没病”——那就很危险啦!

前面扯了一堆屁话,终于开始聊 VirusTotal 了。 相比传统的杀毒软件,VirusTotal 具有完全不同的商业模式——它自己并【不】研发杀毒软件。 它的玩法是——把全球各种杀毒软件汇总到它的服务器上,然后提供一个 Web 界面给大伙儿使用。你如果怀疑某个文件有问题,可以把这个可疑的文件提交到它的网站上进行扫描。然后 VirusTotal 会告诉你,全球各大杀毒软件对这个文件的扫描结果,让你参考。 前面说了:【漏报】更危险。因此先来说这个优势。 由于 VirusTotal 汇总了全球所有主流/知名的杀毒软件;因此,可以最大程度的降低【漏报】。 说得直白一些:如果 VirusTotal 查不出来,你自己电脑上的杀毒软件更加查不出来。 但要提醒大伙儿:虽然 VirusTotal 汇总了全球主流的杀毒软件,它依然不是【全能】滴。依然有可能出现——某个恶意软件,VT 上所有的引擎都没查出来(全部漏报)。在本文末尾的“高级话题”会聊这点。 一般来说,【误报】属于某个具体的杀毒软件的缺陷——通常是其【特征库】在汇总某个特征时,没有做到【独特性】,才导致误报。 由于 VirusTotal 汇总了全球所有主流/知名的杀毒软件,这么多杀毒软件,不可能同时都对同一个文件产生误报。因此,VirusTotal 有助于帮你判断,某个文件的“报毒”到底是不是误报? 具体的判断经验,俺在本文后续章节还会聊。 在10年前,采用类似的原理(汇总一堆杀软)进行 Web 查毒的网站,不止 VirusTotal 一家。如今,其它几家已经消亡/没落;而 VirusTotal 因为做得最好,在2012年被【Google】收购。 有了 Google 这个后台老板,VirusTotal 可以获得更好的基础设施(比如更牛逼的服务器集群);因此,它可以在【免费】的前提下,提供更好的服务。比如说:让你能上传更大的文件,而且扫描速度会更快…… 因为有了 Google 这个靠山,也会有更多的安全厂商主动要找 VirusTotal 合作,从而让前面两个优势更明显。
要使用 VirusTotal 扫描文件,先猛击如下网址:
然后你会看到如下界面,点击界面中的“Choose file”按钮,会提示你选择本地硬盘的某个文件。

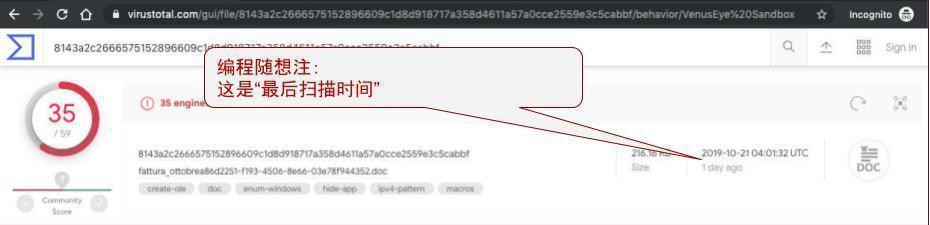
如果你提交的文件属于【首次提交】(也就是,之前【没人】提交过同样的文件),那么当你上传之后,VirusTotal 会立即进行一次扫描; 反之,如果你提交的文件,之前已经有人提交过。那 VirusTotal【不会】进行扫描,而是直接显示“最后一次扫描结果”。
(最后扫描时间)
有些好奇的同学可能会问:VT 如何判断【相同文件】捏? 简而言之,VT 根据散列算法(SHA256)判断文件是否相同。如果你不晓得“散列算法的概念及原理”,可以参考如下博文:
当你企图上传某个文件时,VT 界面上的 JS 代码会先在你本机计算该文件的 SHA256 散列值,然后拿计算结果去 VT 网站的数据库进行查找,如果这个散列值/哈希值已经存在,说明相同的文件曾经被上传过,就不需要重新上传,直接跳到“最后一次扫描结果”的界面。
(扫描结果界面中的 SHA256 散列值)

“去重”的好处有很多,比较直接的一个优点是“提升性能”。如今的文件越来越大,上传所需的时间也就越久,同时也越消耗 VT 服务器的资源。避免上传重复的文件,既提升用户体验,也降低 VT 服务器的开销。 很多技术菜鸟抱怨说:不晓得如何判断【误报 or 漏报】。 俺大致说一下(个人经验,仅供参考) 对于“误报 or 漏报”的判断,很难给出某个绝对的标准,需要综合若干因素,并结合自己的经验。 最主要的指标是“报毒引擎的数量”,但这【不是】唯一的参考依据(下面会说)
“报毒引擎数”≤ 4个
考虑到如今 VirusTotal 已经整合60~70个引擎,如果只有 1~4 个引擎报毒,通常说明:是这少数几个引擎的【误报】。
5个 ≤“报毒引擎数”≤ 8个
当“报毒”的引擎不止两三个,而是达到说5~8个,这时候你需要关注一下“报告结果”的【差异度】—— 如果报告的结果【完全不同】。对这种情况,还是【误报】的可能性更大; 反之,如果这几个报毒的引擎,报告的结果指向【同种恶意软件】,那就要小心啦(确诊的可能性比较大了)
“报毒引擎数”> 8个
如果“报毒”的引擎数量更多,不论报告的差异度如何,你都应该小心了。因为这么多个引擎【同时】出现误报的可能性【很低】。 再次强调: 上述几个阈值(临界值),纯属个人经验。不同的人,对安全性的要求不同,这几个阈值可以适当微调。 说到“差异度”,这里面有一个比较蛋疼的问题——不同的厂商对【同一个】恶意软件,可能会有不同的叫法。在如下截图中,有高达26个引擎报毒,显然属于【确诊】。但如果你观察这些厂商报告的名称,会发现有很多厂商称之为“Ursu”;还有很多厂商称之为“InstallCore”。
(同一款恶意软件,不同厂商的叫法,可能会有差异)

那如何解决“名称差异”这个问题捏?这只能凭你自己的经验啦。 最近十年来,经常有读者抱怨一个问题——某些【国产的】杀毒软件,会对“翻墙工具”进行【故意误报】。 所谓的【故意误报】,就是明知某软件很正常,却故意要说它不正常。(【国产】杀毒软件这么干,原因你懂的) 所以,对“翻墙工具”的病毒扫描,要以【国外的】杀毒软件为准。 (经某热心读者提醒,特补充这段) 如今 VT 上整合的杀毒厂商越来越多,某些厂商使用的引擎,其实是贴牌 OEM(购买了别家的引擎,贴自己的 logo) 这种情况会导致:“误报引擎数”增多,并影响到俺上述的判断标准。也就是说,如果某个引擎误报,OEM 该引擎的其它厂家,也会有【完全一样】的误报。
比如说:你收到别人发给你的某个网站/网址;你担心这个网站/网址有安全风险,那就先用 VirusTotal 扫描一下。 界面操作的示意图如下:

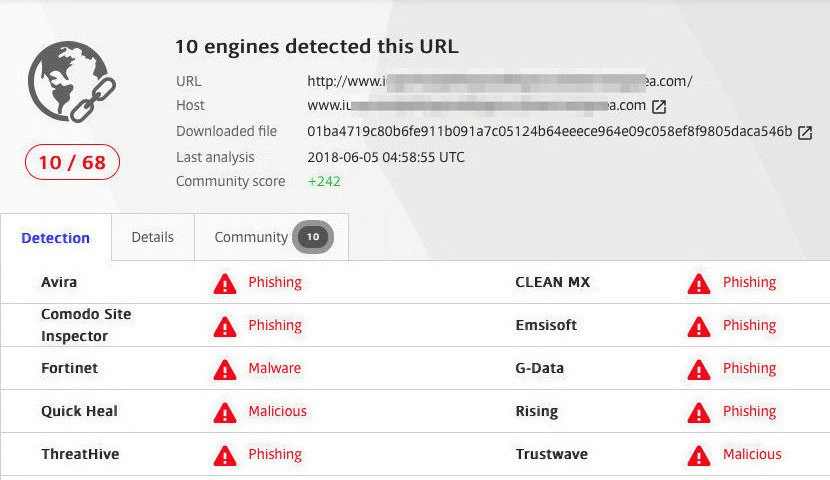
对“假阴性 or 假阳性”的判断经验,大致参考前一个章节(此处就不再浪费口水啦) 顺便分享一张示意图,是某钓鱼网站的扫描结果。
(某个钓鱼网站的扫描结果)
前面聊“扫描文件”时提到了:某些【国产引擎】会对翻墙工具进行【故意误报】。 基于同样的道理,【国产引擎】完全有可能会对某些国外的“反党反共”站点进行【故意误报】(即使现在没有这么干,也不排除未来会这么干)。 因此,对于这类站点,应该以【国外】的引擎作为主要参考依据。
在前面的章节曾经提到:
如果你提交的文件属于【首次提交】(也就是,之前没人提交过同样的文件),那么当你上传之后,VirusTotal 会立即进行一次扫描;
反之,如果你提交的文件,之前已经有人提交过。那 VirusTotal【不会】进行扫描,而是直接显示“最后一次扫描结果”。
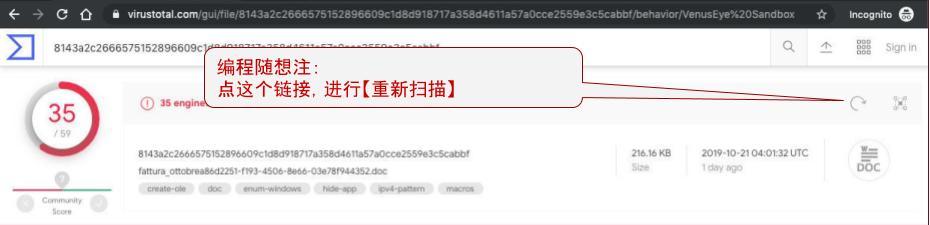
假设你要强制 VT 【立即进行】一次扫描,可以点击界面右上角的某个按钮(示意图如下)
(“重新扫描”的按钮)
为啥需要“重新扫描”捏?因为杀毒引擎的特征库会频繁更新。所以,有可能某个恶意软件,之前【没被】扫描出来;但后来杀毒引擎更新了病毒特征库之后,就能够检测出它。 在扫描结果的页面上,有个【DETAILS】按钮,点击该按钮会切换到【详细信息】的界面,其中就包括该文件的“扫描历史”。 通过“扫描历史”,你可以知道该文件的如下信息:
第一次上传时间(First Submission) 最近一次上传时间(Last Submission)
最近一次扫描时间(Last Analysis)
“最近一次上传时间”与“最近一次扫描的时间”可能会不同。因为如果有人点击过(界面右上角的)reanalyze 按钮进行重新扫描,此时并没有出现“上传”的行为——“最近一次扫描时间”会变,而“最近一次上传时间”不变。 重复扫描“网站/网址”,其操作基本类似于“重复扫描文件”,此处就不再浪费口水啦。 所谓的“搜索”指的是——查找别人曾经扫描过的“文件、网站”,了解其扫描结果。 界面操作的示意图如下:
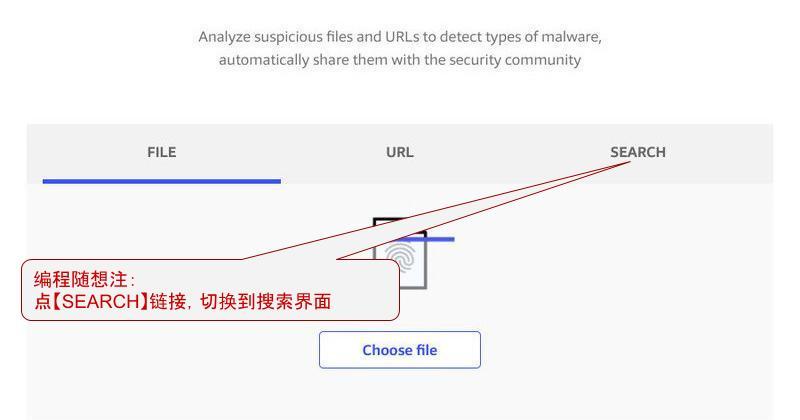
大致有如下几种:
1、散列值(针对文件,散列值可以是:SHA256、SHA1、MD5) 2、网址(针对网站)
3、域名(针对网站)
如何获得某个文件的散列值,请参考如下博文:
《扫盲文件完整性校验——关于散列值和数字签名》 顺便说一下: 以【散列值】的方式搜索某文件的扫描结果,有一个不太明显的好处——你只需知道文件的散列值,【不】需要实际拥有这个文件。 猛击如下网址,会进入 VirusTotal 的复古界面。
https://www.virustotal.com/old-browsers/
“复古界面”相比“正式界面”,显得更加简洁(或者说,更加丑陋)。该界面【没】图片,加载速度也【更快】。
(复古界面的截屏)
如下几种情况,可能会用到复古界面 1、某些同学以翻墙的方式访问 VirusTotal,并且翻墙速度是【龟速】 2、某些同学为了安全性,禁用了浏览器的某些特性(比如禁止显示图片) 3、某些同学就是喜欢【终端风格】的感脚
对于上述第3类同学,悄悄透露一个 hacks 技巧。这个复古界面的网址,支持 style 参数,可以用来调整配色风格。比如下面这个网址,可以把配色调成老式终端的那种绿色。
https://www.virustotal.com/old-browsers/?style=1337 想知道复古界面总共支持哪些配色风格?请直接查看 HTML 源代码,便可知晓。 对于那些 VirusTotal 的重度用户(频繁使用它进行扫描),可以考虑如下几个辅助工具; 另外,如果你有一些特殊需求,如下的某些辅助工具,或许对你有用。 官方提供了 Chrome & Firefox 的浏览器扩展,网址如下: Chrome
https://chrome.google.com/webstore/detail/efbjojhplkelaegfbieplglfidafgoka
Firefox
https://addons.mozilla.org/en-US/firefox/addon/vt4browsers/
安装了上述扩展之后,当你右击某个超链接,在快捷菜单中会增加几个菜单项,方便你直接把该链接提交到 VT 进行扫描。 “VirusTotal 扩展”的另一个用途是——当你从网上下载某个文件,该扩展会询问你:保存之前是否先提交到 VirusTotal 进行扫描?
VirusTotal 提供了一个公开的邮箱 scan@virustotal.com 用来接受扫描的样本。也就是说,你以【邮件附件】的方式,把某个文件发送到该信箱,然后 VirusTotal 会给你一封回信,包含对这个文件的扫描结果。 以这种方式提交附件,附件的尺寸上限是【32MB】(未来可能会增加这个上限)。
你发送的邮件,【标题】必须是 SCAN 或者 SCAN+XML 这两种。对于前者,你收到的回信是【纯文本】格式,对于后者,你收到的回信是【XML 格式】。(对 XML 格式的详细说明,参见 VT 官网的“这个链接”)
VirusTotal 官方开发过三大主流桌面系统的客户端(Windows、Mac OS、Linux)。官网页面的链接在“这里”。页面中有客户端的下载网址。 在上述帮助页面中提到:Windows 的客户端在2017年已经【停止开发】(既然已经停止维护,俺【不】建议使用它), 另外,VT 官方【没有】提供手机 App。目前市面上针对 VT 的 App 来自第三方。
在其官方的帮助页面(链接在“这里”)有如下这段免责声明:
VirusTotal can also be used through a smartphone app.
VirusTotal is about empowering the Community in order to build tools that will make the Internet a safer place, as such, we like to credit and feature Community-developed goodies that help the antivirus industry in receiving more files in order to have more visibility into threats. Below you can find links to apps that will allow you to interact with VirusTotal making use of your smartphone, note that these are not developed by VirusTotal itself and so we are not responsible for them.
VirusTotal 提供了一些 API(编程接口),你可以通过“自己写程序”的方式,调用它的 API,从而实现【自动化】的扫描或搜索。
如果你是个程序猿/程序媛,并且对它的 API 感兴趣,可以访问 VT 官方的仓库(在 Github,链接在“这里”)。
根据俺一贯的风格,当然要提及【隐私的防范】。 由于 VirusTotal 支持【重复扫描】的功能(reanalyze)。显然,所有上传的文件都会【永久存储】在 VT 的服务器上。 因此,如果你要扫描的文件包含了某些【个人隐私信息】,就需要权衡一下——要不要上传到 VT? 请注意:VT 已经被 Google 收购很多年。因此,所有上传到 VT 的样本文件,可能会被 Google 拿去做大数据分析。 当你使用 VirusTotal 的时候,VT 服务器肯定会记录并长期保存你的“访问者 IP”(为啥 VT 要长期保存访客 IP?在末尾的【高级话题】会聊到) 如果你【没】用代理,VT 服务器看到的“访问者 IP”也就是你的【真实公网 IP】——这显然也属于“隐私风险”。 一般用户无需担心这个问题;但如果你对【隐私】的要求很高,【不】希望 VirusTotal 看到你的“真实公网 IP”,那就以【代理】的方式访问它。 顺便分享一下俺的情况—— (博客的老读者应该都知道)俺上网是【全程】走 Tor 代理(即使访问国内网站,也是如此)。因此,当俺访问 VirusTotal,它的服务器只会看到 Tor 网络的【出口节点】的 IP 地址。 Tor 虽然极大提升了【隐匿性】,但缺点之一是:很多网站对 Tor 不太友好。前几年,VT 也对 Tor 不太友好(经常会要求进行“reCAPTCHA 人机验证”);最近一两年,好像变得更友好了(碰到“人机验证”的次数显著降低) 前面提到了“以邮件方式提交文件”。如果你采用这种方式,显然,VirusTotal 会看到你的【邮箱地址】。 很多人有【思维定势】,觉得 VirusTotal 这种网站只能用于安全目的。其实不然。 如果你的思路足够【发散】,应该能想出一些另类的用途。 此处所说的“元数据”,指的是【文件内容】中包含的某些属性信息。比如说:当你打开某个 PDF 文件,通常可以在 PDF 阅读器的菜单中找到“文档属性”之类的功能,该功能显示的“文档属性”也就是 PDF 的元数据。 不同格式的文件,“元数据”也各不相同,“查看元数据的工具/方法”当然也各不相同。对于技术菜鸟而言,如何查看不同格式的文件的元数据,是比较难办滴。 而 VirusTotal 的一个好处是:它在显示某个文件的扫描结果时,会顺带把该文件【所有的】元数据都列给你看。 因此,VirusTotal 也就成了一个【通用的】“元数据查看工具” :) 再次提醒: 前一个章节提到【隐私】的话题。如果你要查看元数据的文件,属于你个人的私密文件(比如:不想公开的个人照片)。用 VT 的方式就不合适。 前面已经介绍了【搜索】功能。
在搜索框中,你不但可以输入“散列值 or 网址”,还可以输入【域名】(比如说,俺博客的域名是 program-think.blogspot.com)。如果你搜索的是域名,VirusTotal 可以显示该域名的很多信息,比如:
DNS 解析记录 地址解析随时间的变化 Whois 信息 该域名还有哪些同级域名(兄弟域名) 如果该域名支持 HTTPS,还会显示 CA 证书的详情
……
最近一两个月,受疫情的影响,俺多出一些闲暇时间,就分享了很多电子书(电子书清单),正好来聊聊这个话题。 当俺去网上搜电子书的时候,经常会碰到一个“选择的困境”——同一本书的同一个版本,可能会找到好几个不同的文件。 由于俺精力有限,无法逐个进行详细比对。为了偷懒,俺倾向于——先分享那个流传比较广的文件,也就是【活跃度】比较高的。(从统计学的角度)活跃度高的,质量更好的【概率】也比较大。 那么,如何判断两个文件的活跃度捏?有一个简单的(粗糙的)办法,拿去 VirusTotal 扫描一下。由于 VirusTotal 已经有巨大的用户群,它可以作为某种参考系。 假设同一本书的2个 PDF,其中一个曾经被 VT 扫描过,另一个没有;通常说明,前者的活跃度比较高。 如果这2个 PDF 都曾经被 VT 扫描过,【首次】扫描时间更早的那个,活跃度更高。 注: 用这个玩法要注意:你对比的几个文件,需要有【相同】的“时间参考系”。 比如俺上述例子中,对比的是同一本书同一个版本的多个电子版。因此,这些电子版文件,理论上的创建时间肯定在此书出版时间【之后】。 该书的出版时间,也就是所谓的“时间参考系”。 上述几个玩法,是用处比较大滴,俺分享出来。 还有一些另类的玩法,因为太小众了,俺就不说啦。 (这个章节写给【高风险人士】;如果你不属于这类人,本章节可以不用看) 最近10年,俺写了很多信息安全的博文,读者里面也有一些安全领域的高端人士。如果只聊前面那些扫盲性质的话题,显然不能满足这类读者的胃口。 为了避免被这些高端读者吐槽,俺在本文的末尾,聊一点稍微“阳春白雪”的话题——主要是针对【高危人士】的经验。 俺所说的“高风险人士/高危人士”,换个说法就是“高价值目标”。因为当你的价值高,攻击者如果搞定你的“数字资产”(PC、手机、帐号…),收获会很大。因此,“高价值目标”所面临的【攻击力度】会远远大于普通网民。其“高风险”就来自于此。 很多人【误以为】“高价值目标”就是“技术高手”。其实不然!“高价值目标”不一定是“技术高手”;反之“技术高手”也不一定是“高价值目标”(关于这个误解,俺曾经在某篇博文中澄清过) 比如说某些处于关键岗位的政府官员,不一定是技术高手,但属于高价值目标;同理,某个重要公司中处于关键岗位的人,也是这种情况。
在去年(2019)那篇《如何【系统性学习】——从“媒介形态”聊到“DIKW 模型”》,俺特地强调了【换位思考】的重要性。在信息安全领域,不论你处于“攻/防”的哪一边,你都需要换位思考(关于这点,俺在评论区与读者交流时,也强调过)
当你想要提升【安全防范】,你就需要站在攻击者的角度思考问题。既然今天聊得是 VirusTotal 的话题,你需要知道——攻击者如何利用 VirusTotal 来辅助攻击? 在俺聊之前,建议你自己先琢磨一下(这可是个锻炼思维能力的机会哦) 给 你 一 柱 香 的 时 间 思 考 这 个 问 题 , 先 别 急 着 往 下 翻 页 :) 这是最容易想到的一招。 如果你是一个攻击者,你想发一个木马给某个重要目标。你当然希望【一击得手】。而要提高成功率,就要确保自己发过去的木马,不会被对方的杀毒软件检测出来。因此,攻击者很容易想到——先用 VirusTotal 检查一下自己制作的木马。 一个高级的攻击者(或攻击者团队),肯定具备编程能力(开发软件的能力)。因此,他们可以自己开发一个木马。开发完成后,先用 VirusTotal 查毒;如果被查出来,就继续完善,然后再用 VT 查;如此循环多次,一直完善到 VT 彻底查不出。 当然啦,要让 VT 完全查不出某个木马,攻击者(攻击团队)需要牛逼到一定程度。这样的攻击者(攻击团队)肯定存在;而且这样的攻击者(团队),通常【不】屑于攻击普通网民(因为价值不够高)。他们要攻击的,肯定是【高价值目标】。 这种玩法并【不是】俺个人的臆想,著名的《Wired》(连线杂志)曾经发过一篇报道(如下),就提到了俺刚才那个玩法。
《A Google Site Meant to Protect You Is Helping Hackers Attack You @ Wired》
那么,VirusTotal 方面如何知道攻击者在利用 VT 进行测试捏?因为 VT 的数据库,除了会保存上传的文件,还会保存上传者的“公网 IP”,以及其它一些信息(这也就回答了俺在前面章节提及的“隐私问题”) 请允许俺稍微跑题一下: 上述文章提到说:某些国家级骇客(比如天朝的御用骇客)会使用【相同的公网 IP】,多次往 VirusTotal 提交包含恶意代码的文件。这种行为显然是攻击者(攻击团队)在拿 VirusTotal 进行测试。因为普通人偶尔才会碰到恶意代码,因此【频繁】提交含有恶意代码的文件,这种可能性【几乎不存在】。 看到这里,俺猜测某些读者会纳闷了:那些国家级的骇客团队,难道不使用【代理】吗? 俺之所以跑题,想聊的就是这个——
多年前曾经发过一篇《每周转载:天朝【御用骇客】是如何暴露的?》,其中涉及到天朝的【军方骇客团队】(番号:61398部队,隶属总参三部二局),他们也是因为一些低级失误(公网 IP、帐号关联性、等等) 而暴露身份。说明这种失误【不是】个例。而且,不光天朝的御用骇客出现过这种失误,其它国家也出现过。
那么,为啥“国家队”会出现这种低级失误捏?关键在于【心态】—— 御用骇客是“体制内的人/政府的人”,他们【不用】担心身份暴露的风险。因此,在“隐藏踪迹”方面比较容易松懈(毕竟,人都是有惰性滴)。 相比之下,【民间】的攻击者,暴露身份的代价就很高(比如坐牢)。因此,他们就有更强的动力去做“隐藏踪迹”的措施。俺本人为啥要在【防范】方面花很多精力,原因也在于此。
引申阅读:《为啥朝廷总抓不到俺——十年反党活动的安全经验汇总》
咱们天朝有句老话叫做【知己知彼】。如果你是一个攻击者,你当然想要知道:攻击目标的【安全防范意识】。 由于 VirusTotal 的用户群已经非常大,很多安全防范意识较高的人,都会利用它扫描文件或网站。如果目标人士有“经常使用 VT”的习惯,能在某种程度上反映此人的安全意识。 为了判断对方是否习惯于使用 VT,你可以先用某种方式(邮件、IM、等)让对方得到一个【完全无害】的文件,并且该文件是【全新】滴。所谓的【全新】意味着——在这之前,不可能有人在 VT 上提交过相同的文件。如果你的攻击目标在得到该文件之后,上传到 VT 进行扫描,就会在 VT 上留下一个【扫描历史】。你作为攻击者,只要定期去 VT 查询该文件的散列值,就能判断出:对方拿到该文件之后,有没有提交到 VT 进行扫描。从而判断出:对方的“安全防范意识”是否足够高。 前面聊的2招,都是针对“文件扫描”。接着再来谈谈“网站扫描”。 普通网民使用 VirusTotal 扫描某个网址(URL),主要是担心该 URL 对应的网站存在“挂马”的风险。 如果你是一个攻击者,你搭建了一个网站进行【挂马攻击】。你当然要考虑到,你的攻击目标可能会用 VirusTotal 检测你发过去的网址。 那么,一个足够高明的攻击者(攻击团队)会怎么做捏?其实很简单! VirusTotal 要检测某个网址(URL),当然先要获取该网站的网页内容。这个过程就类似于“搜索引擎的爬虫”。 因此,那些高明的攻击者(攻击团队)在搭建好挂马的服务器之后,但【还没】放木马之前,自己先把这个服务器的网址提交到 VT 进行检测。一旦提交,VT 的网页爬虫马上就会来抓取该服务器的网页。于是,攻击者(攻击团队)就可以在服务器上分析“VT 网页爬虫的行为”—— 比如说:“VT 网页爬虫”使用的公网 IP 是啥?(只要测试足够多次,就能汇总 VT 公司使用的【所有】公网 IP) 比如说:“VT 网页爬虫”解析网页的行为与真实浏览器的解析行为,有哪些差异? 比如说:“VT 网页爬虫”内置的“JS 引擎”(JS VM)与真实浏览器的“JS 引擎”,有啥区别? …… 当攻击者(攻击团队)收集了足够多“VT 爬虫的特征”,他们就可以在自己的服务器上进行【区别对待】——如果判断出访问者是“VT 爬虫”,就显示【完全无害】的网页内容;反之,如果是正常的用户浏览器,就推送木马,使之中招。 此招数的奥妙在于——就算受害者的防范意识比较【强】,先用 VT 检查收到的网址,VT 也会报告说“一切 OK”。从而使得那些防范意识较强的目标,也放松警惕。 针对上述介绍,俺稍微总结一下:
(如果你是高价值目标),【不要】过于相信 VT 关于“无毒”的检测结果。
但反过来,如果 VT 上有【足够多引擎】报毒,那么这个结论肯定是可信滴(真实阳性)。 简而言之,(如果你是高价值目标)VT 可以帮你确诊,但无法帮你排除。 下面这些措施,主要针对“高价值目标”;普通网民姑且听之,不要因此而受到惊吓 :) 如果 VT 的结果不够可信(无法帮你排除),那咋办捏?
对于【文件】
当你得到一个可疑的文件,而且因为某种原因,你又需要打开/运行该文件。那么,在一个【专用】且【网络隔离】的虚拟机中进行,会比较保险。(没玩过虚拟机的同学,可以先看《扫盲操作系统虚拟机》系列教程)
某些安全要求非常高的同学,可能还会担心“虚拟机穿透”的危险;这些同学可以去玩【物理隔离】这招——专门用一个独立且【网络隔离】的电脑,来打开那些来历不明的文件(关于【物理隔离】,可以参考《如何防止黑客入侵》系列教程的其中一篇) 由于这台电脑是【网络隔离】,你可以用【U盘】在两台电脑之间搬运数据。当然啦,每次都这么干,会有点麻烦。但为了“安全性”,有时候麻烦一点也值得。
对于【网址】
如果别人发给你一个网址,即使你已经用 VT 扫描过,依然要在一个【隔离】的浏览器环境中打开。 浏览器的隔离,分如下几个档次:
基于【浏览器实例】(Profile)的隔离 基于【操作系统用户】(OS User)的隔离 基于【虚拟系统】(Guest OS)的隔离
基于【物理系统】(Host OS)的隔离
越前面的档次,隔离性越差,但更方便;越后面的档次,隔离性越好,但更麻烦。这方面的详细教程,参见《如何保护隐私》系列的其中一篇。
俺博客上,和本文相关的帖子(需翻墙):
《如何防止黑客入侵》(系列)
《如何保护隐私》(系列)
《扫盲操作系统虚拟机》(系列)
《扫盲文件完整性校验——关于散列值和数字签名》
《为啥朝廷总抓不到俺——十年反党活动的安全经验汇总》
《为什么桌面系统装 Linux 可以做到更好的安全性(相比 Windows & macOS 而言)》
《吐槽一下 Windows 的安全漏洞——严重性超乎想象》
《如何对付公安部门的“网络临侦”?——“黑暗幽灵木马”之随想》
《每周转载:天朝【御用骇客】是如何暴露的?》